Vector vs List
How could my crude implementation possibly be faster than STL?
This is an old discovery from 2013. I never published the draft in my old blog, however I still think this is interesting: Using STL algorithms may not be always the optimal solution!
In 2013 I had a lot of free time while applying for jobs in Porto Alegre and was honing my C++ skills programming and listening the gurus talk. Bjarne Stroustrup explained in his keynote to Going Native 2012 that vector performs faster than list for insertions (at least for small elements and long lists) and removals and it makes pretty much sense.
The reason is that a vector operates on one chunk contiguous chunk of memory that can be loaded into cache contiguously. Reallocation and copying data from the old contiguous memory location to the next is backed up by machine instructions. The list on the other hand uses pointers and to jump from the list element to the content to the next-pointer. This happens at almost random addresses thus creating more cache misses than anything else…
It seemed a great exercise, I wanted to know when the speedup by caches is offset by the element size and length of the container. I wrote a small program for basic bench marking. The program generates random numbers and inserts these in ascending order in a container (list or vector). I ran this for combinations of different container and element sizes.
In the first implementation I had my own linear-search to find the position
(called insert_sorted_lin) and I later recalled that STL provides
std::lower_bound() that does exactly what I wanted.
Just out of curiosity and because I already implemented it I left both in the program. I ran the benchmarks and was surprised.
Measurements
I compiled the program with gcc v10.2.1 on Linux x64
(-O3 -march=native -mtune=native). The results have been generated on a
i7-6700 @ 3.4GHz.
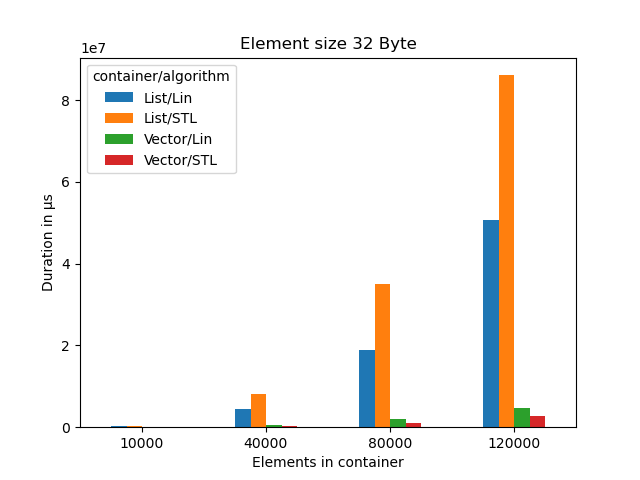
Clearly Bjarne was right here. Vector performs much better than list.
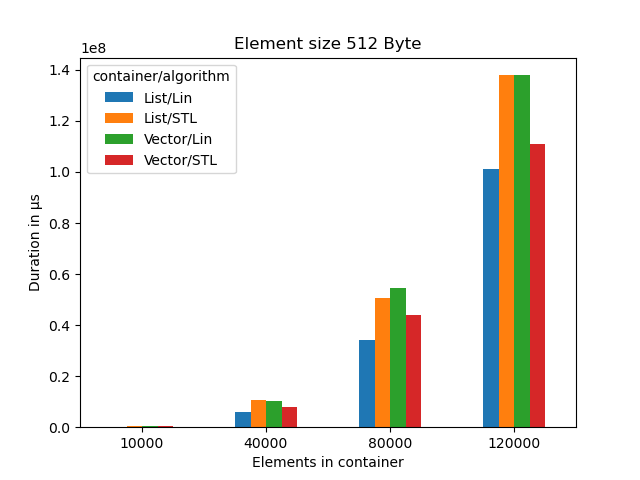
Clearly Bjarne is still right. However we see the costs for copying memory increase. List finally outperforms vector, at least for linear search.
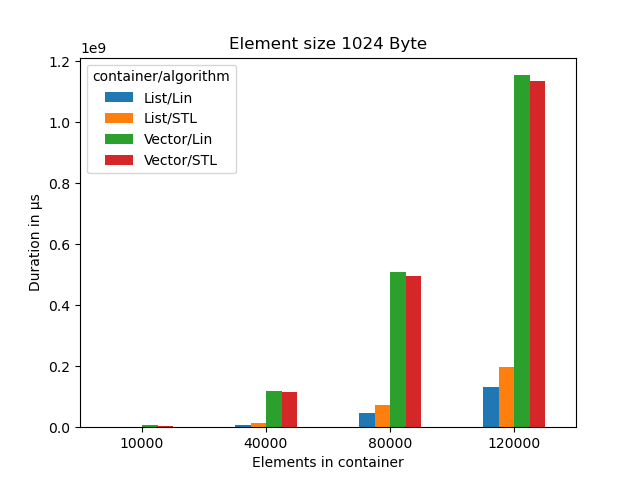
At 1k sized objects list is significatly faster than vector if we have more than 10000 elements.
Why does a linear search outperform a binary search?
Why does std::lower_bound() algorithm from STL perform so much worse on
std::list than a crude linear search?
I asked on a forum (I think it was on LinkedIn C++ group) and got an explanation from user Steve Dirickson:
“
std::advance(_Mid, _Count2);is prohibitively expensive on non-random-access iterators (the only kind available for std::list); on average, you have to pay for increments/touches equal to the number of elements in the list, plus the cost of the log(2)N looks/comparisons that a real binary search performs”
Conclusion
There is even less reason for using std::list use std::vector and don’t look
back. Even with 100.000 elements of 516 Bytes a std::vector still performs as
good as std::list. Plus you can use std::algorithm without penalty.
See: